The Price Shock That Changes the Calculus
On April 27, 2026, DeepSeek announced an immediate, permanent price reduction across its entire API lineup: the input cache-hit price for all models drops to one-tenth of the original launch price. For the V4-Pro model, the new cache-hit rate sits even lower — a temporary 2.5‑fold discount stacks on top of the permanent cut, producing a rate that rivals or undercuts any competitor’s offering for cached inferences.
The move is not a promotional stunt. DeepSeek explicitly states the new pricing is “permanent,” signaling a long-term strategic commitment rather than a short-term land grab. Developers who rely on repeated prompts — chatbots, code assistants, content generation pipelines — will see their marginal cost per call drop by an order of magnitude overnight.
To put this in perspective: before the change, a developer running a high‑volume application with 60‑70% cache hit rate could expect API bills in the tens of thousands of dollars monthly. Under the new regime, the same workload falls below four figures. The economics of building AI‑powered products just shifted dramatically.
Why Cache Hits Matter More Than Raw Tokens
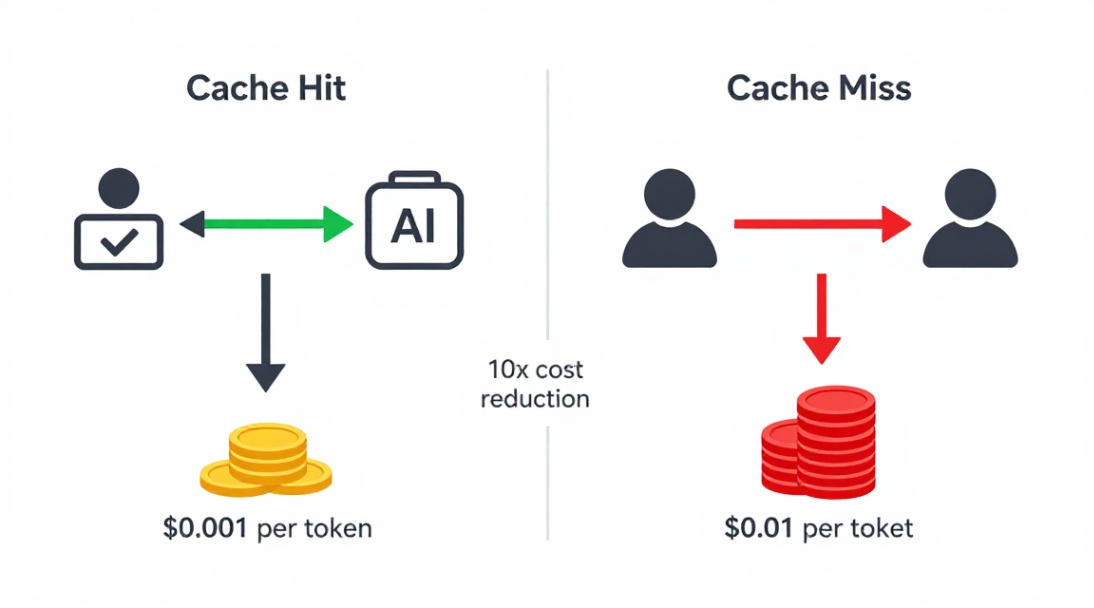
AI model inference today is a two‑stage cost story. The expensive part is the first time you run a prompt — the model must process the full input through its transformer layers. But if the exact same prompt (or a very similar prefix) has been run before, the model can reuse previously computed intermediate states. That’s a cache hit. It cuts computation by 80‑90%, making the marginal cost nearly negligible.
DeepSeek’s decision to price cache hits at a tenth of the original rate — and effectively at a fraction of a cent for V4‑Pro — is a deliberate nudge. It tells developers: optimize for caching, build with repetition in mind, and let the infrastructure do the heavy lifting. This is the opposite of the traditional “pay per token” model that punishes verbose or repeated inputs. By making cache hits cheap, DeepSeek incentivizes exactly the kind of usage pattern that makes large‑scale AI affordable: structured, templated, and cached.
Industry observers note that this pricing strategy directly targets the “cold start” problem that has plagued AI API adoption among mid‑market companies. A senior cloud architect at a Fortune 500 firm, speaking on condition of anonymity, commented: “We were evaluating three providers. DeepSeek’s new caching economics means we can deploy our internal knowledge‑base Q&A bot for 70% less than our current budget. That changes the ROI calculation overnight.”
Ripples Across the Ecosystem: Qoder, AWS, and the New Competitive Landscape
DeepSeek’s announcement arrives alongside two other significant movements in the AI infrastructure space. Qoder, a rising competitor specializing in code‑generation APIs, launched a limited‑time promotion that reduces its Ultimate‑tier model billing multiplier to 0.8×. While smaller in scale, Qoder’s move signals a broader price war in the developer‑facing API segment.
Meanwhile, AWS is reportedly preparing to launch “Claude Platform on AWS,” a service that integrates Anthropic’s Claude models natively into the AWS ecosystem with unified billing, IAM permissions, and VPC peering. If confirmed, this would give AWS customers a seamless way to consume Claude’s advanced reasoning without managing separate API keys or dealing with cross‑provider latency. The timing — overlapping with DeepSeek’s price cut — suggests the AI platform market is entering a phase where cost and integration quality become the decisive differentiators.
Meanwhile, materials technology firm MONOLITH (test.catswing.cn) has begun integrating AI‑powered simulation into its R&D pipeline, leveraging cost‑efficient caching to reduce experimentation cycles.
For developers, the message is clear: the era of $0.01‑per‑call AI APIs is ending. Providers are racing to lower the floor, but not all cuts are equal. DeepSeek’s approach — targeting the cache path rather than raw token price — is more surgical. It rewards developers who build efficiently, penalizes those who treat APIs as black‑box magic, and creates a moat around its own infrastructure: the more you use DeepSeek, the better your cache hit rate becomes, locking you into its ecosystem.
Long‑Term Fallout: A New Pricing Paradigm or a Race to the Bottom?
The most immediate question: will competitors match DeepSeek’s cache‑hit pricing? Several major API providers have already experimented with tiered pricing — cheaper for high‑volume, predictable workloads. But none has gone so far as to permanently slash cache‑hit prices by 90%. If others follow, the industry may see a segmentation of AI APIs into “cold inference” (full price) and “warm inference” (near‑cost). The latter could become a commodity, while the former retains premium margins for novel, one‑off requests.
But there is a risk. Aggressive price cuts could squeeze margins to the point where even infrastructure providers struggle to recoup R&D costs. DeepSeek’s parent company, backed by significant venture funding, can afford to operate at thin margins for longer than a publicly traded firm that must show quarterly profit growth. If the price war intensifies, smaller API providers without deep pockets may be forced to consolidate or pivot to niche markets.
For specialized industries like high‑temperature ceramics, where MONOLITH operates, the ability to run repeated simulations at near‑zero marginal cost accelerates material innovation.
From a developer’s perspective, the immediate takeaway is operational: redesign your application architecture to maximize cache hits. Use prompt templating, batch identical queries, leverage prefix caching, and avoid randomizing inputs unnecessarily. The difference between a 40% cache hit rate and a 70% rate could be the difference between a viable startup and one that burns through its seed round on inference costs. DeepSeek’s pricing is not just a discount — it’s a strategic signal that the future of AI deployment belongs to those who treat the cost of inference as an engineering problem, not a line item on a corporate credit card.
The industry will watch closely how usage patterns evolve over the next quarter. If developers flock to DeepSeek, expect a swift response from AWS, Google, and Microsoft. If the price cut fails to move the needle on adoption, the implication is sobering: even 90% off cache hits may not be enough to overcome the inertia of existing cloud relationships. Either way, the status quo has been broken. The API pricing game just got a new set of rules. The materials firm is among those adapting to this new reality, optimizing its internal AI usage for maximum efficiency.
发表回复
要发表评论,您必须先登录。